💬 Baixar e conversar com seu 1o modelo
Chegou a hora do "uau": vamos baixar um modelo de verdade, abrir um chat e ver a IA responder na sua maquina. Dois comandos resolvem — um pra baixar, outro pra conversar — e no fim voce desliga a internet e o modelo continua respondendo.
⬇️ Baixar o modelo
Com o Ollama ja instalado (modulo 2.1) e o modelo escolhido (modulo 2.2), o primeiro passo e baixar o modelo pro seu disco. Vamos usar o qwen3:30b-a3b-q4_K_M — o modelo "rapido" recomendado, com cerca de 18 GB. O download e a unica etapa que pede internet; depois disso, o modelo roda 100% offline.
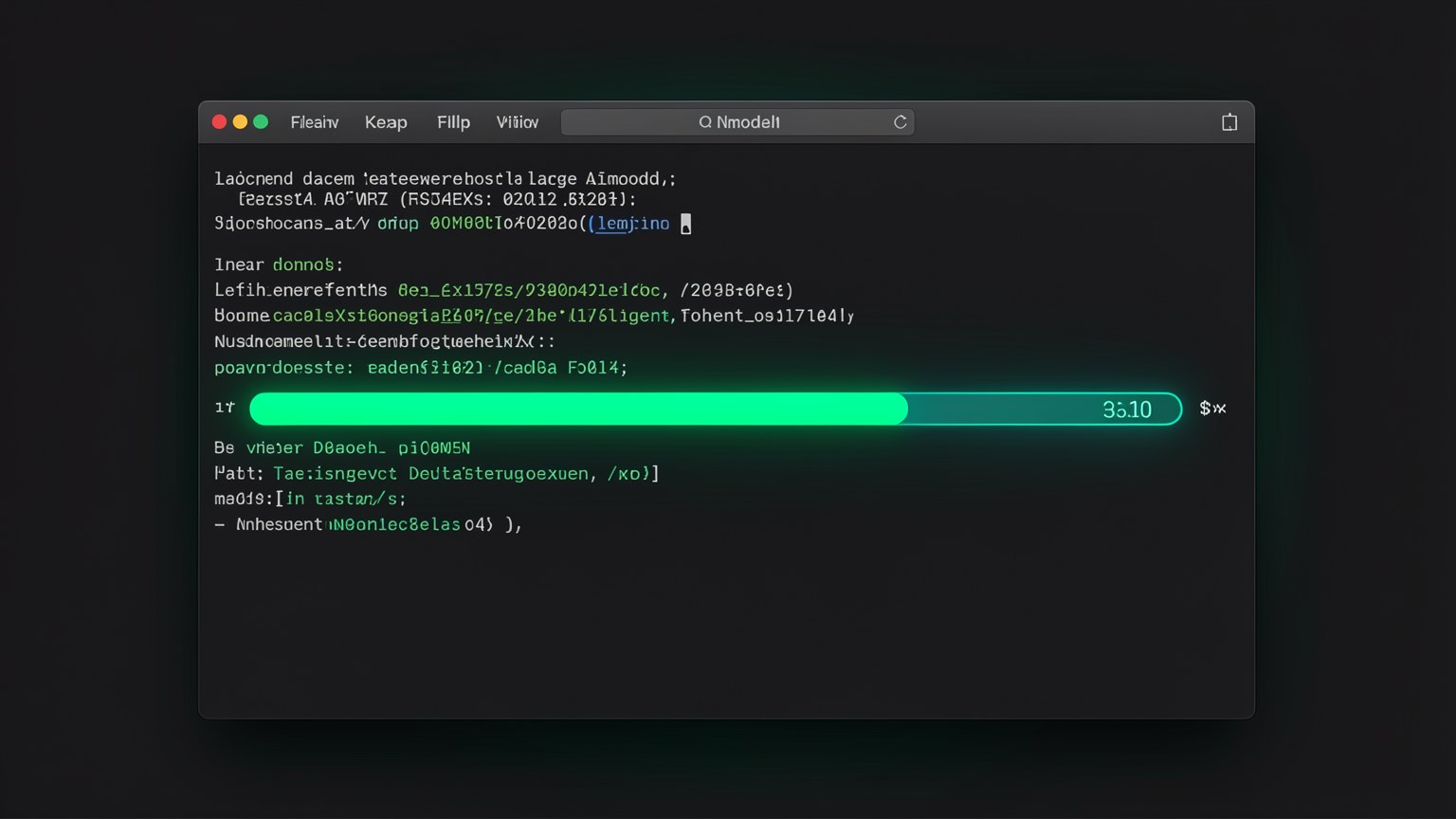
🎯 Code-run: baixar o modelo
Objetivo: trazer o modelo rapido pro seu disco. Cole no terminal:
ollama pull qwen3:30b-a3b-q4_K_MComo verificar: aparece uma barra de progresso ate success. Depois, ollama list deve mostrar o modelo na lista.
Novo aqui? "Pull" (puxar) e o termo do Ollama (emprestado do Git/Docker) para baixar um modelo do repositorio oficial pro seu computador. O nome qwen3:30b-a3b-q4_K_M e a "tag": qwen3 = familia, 30b = 30 bilhoes de parametros, a3b = arquitetura, q4_K_M = nivel de quantizacao (compressao).
Conceitos-chave
O comando que baixa um modelo pro seu disco.
O tamanho do qwen3:30b-a3b-q4_K_M; precisa de espaco em disco.
So usa internet uma vez; depois roda offline.
familia:tamanho-arquitetura-quantizacao.
💬 Conversar no terminal
Modelo baixado, hora de conversar. O comando ollama run abre um chat dentro do proprio terminal: voce digita, da Enter, e o modelo responde ali mesmo. Para sair da conversa, digite /bye.
🎯 Code-run: conversar no terminal
Objetivo: abrir um chat com o modelo e fazer a primeira pergunta. Cole:
ollama run qwen3:30b-a3b-q4_K_M
>>> Explique em uma frase o que e uma janela de contexto.
... (a resposta aparece aqui) ...
>>> /byeComo verificar: o prompt muda para >>> e o modelo responde. /bye te devolve ao terminal normal.
Da esquerda pra direita: pull baixa uma vez, run abre o chat, voce conversa no prompt >>> e /bye encerra. So o "pull" precisa de internet.
💡 Dica pratica
Se voce rodar ollama run com um modelo que ainda nao baixou, o Ollama baixa automaticamente antes de abrir o chat. Mas separar o pull (baixar) do run (conversar) deixa mais claro o que esta acontecendo.
Conceitos-chave
Abre um chat com o modelo no terminal.
Onde voce digita suas perguntas.
Sai da conversa e volta ao terminal.
run baixa o modelo se ele ainda nao existe.
🖼️ Conversar no app
Nao curte terminal? Sem problema. O app do Ollama tem uma janela de chat parecida com qualquer app de mensagem: voce escolhe o modelo numa lista e conversa com o mouse e o teclado, sem digitar comandos. O motor por baixo e o mesmo — muda so a interface.
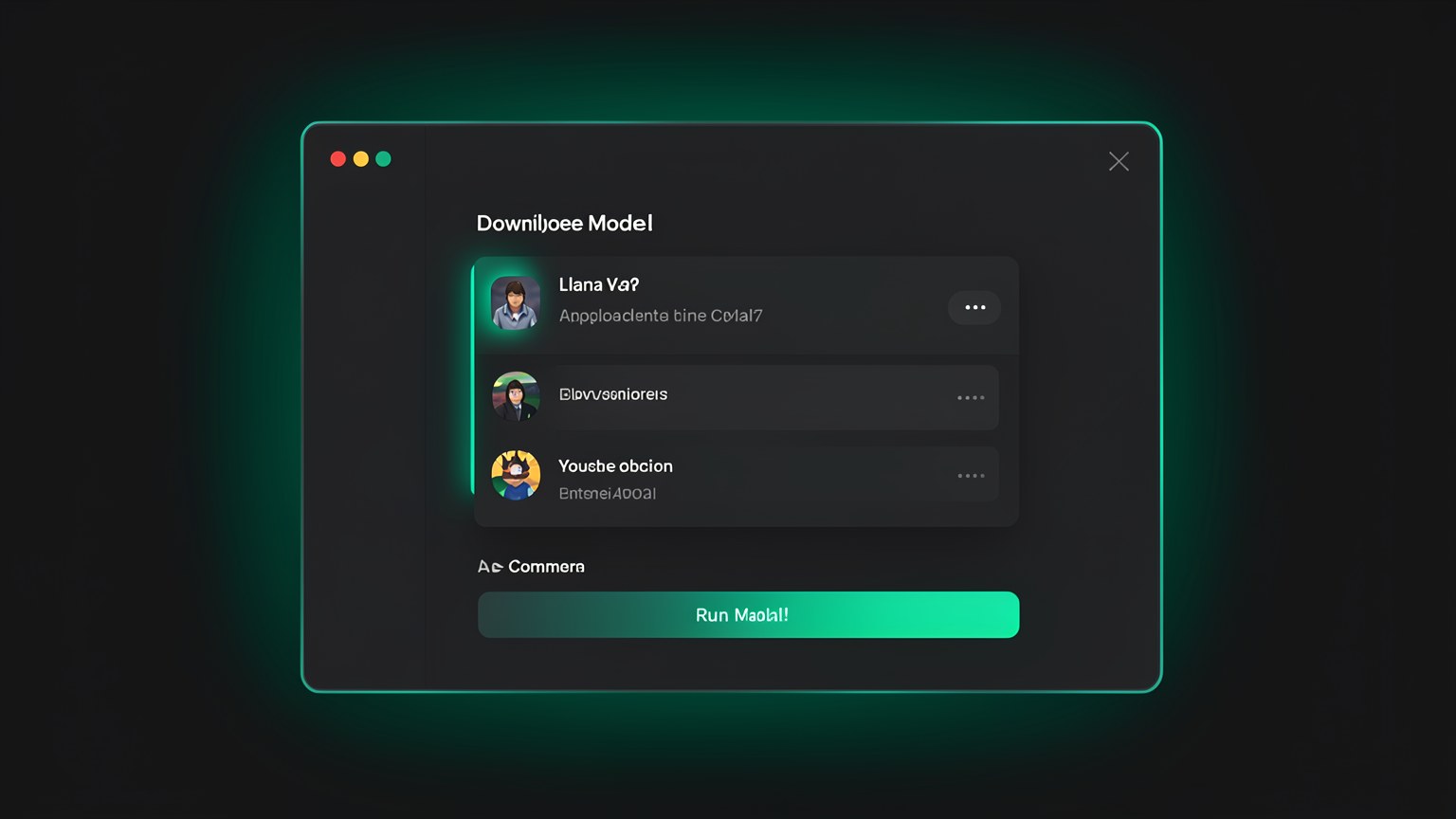
qwen3:30b-a3b-q4_K_M do terminal — app e terminal compartilham os modelos baixados, voce nao baixa duas vezes.✓ Quando o app brilha
- ✓Quem prefere clicar a digitar comandos.
- ✓Conversas longas, com historico rolavel.
- ✓Trocar de modelo num menu, sem decorar tags.
- ✓Mostrar pra alguem sem assustar com o terminal.
✗ Quando o terminal vence
- ✗Automatizar (scripts, pipelines).
- ✗Ver mensagens de erro detalhadas.
- ✗Rodar comandos como pull/list/rm direto.
- ✗Conectar ao agente (o Hermes fala via servico/terminal).
Conceitos-chave
Interface grafica do Ollama.
Os modelos baixados aparecem pra selecionar.
App e terminal usam os mesmos modelos.
Conversa sem digitar nada no terminal.
🧠 O "thinking"
Voce vai notar que, antes de responder, o modelo as vezes mostra algo como "Thought for 6.2 seconds". Isso e o thinking (raciocinio): modelos modernos "pensam" em silencio antes de escrever a resposta final. Esse passo extra costuma deixar a resposta mais correta — em troca de um pouquinho mais de tempo.

📊 O que o "thinking" muda
- •Respostas melhores: raciocinar antes reduz erros em tarefas dificeis.
- •Um pouco mais lento: os segundos de "Thought for..." sao o custo do raciocinio.
- •Configuravel: no Hermes, os toggles Thinking/Fast deixam voce priorizar qualidade ou velocidade.
Novo aqui? "Thinking" (ou "reasoning") e quando o modelo gera um rascunho de raciocinio interno antes da resposta final. Voce ve o rotulo do tempo, mas o rascunho costuma ficar oculto. Modelos com thinking tendem a acertar mais em logica, matematica e codigo.
Conceitos-chave
Raciocinio interno antes da resposta.
O tempo que o modelo passou pensando.
Pensar mais acerta mais, mas demora um pouco.
Toggles do Hermes pra escolher o equilibrio.
⏱️ Velocidade e o 1o load
A primeira pergunta depois de abrir o modelo costuma demorar mais. Isso e o 1o load (carregamento inicial): o Ollama precisa carregar os 18 GB do modelo do disco pra memoria. Da segunda pergunta em diante, com o modelo ja "quente" na RAM, as respostas saem bem mais rapido.
Cold start (1a vez)
O modelo carrega do disco pra RAM — a primeira resposta demora mais.
Modelo quente
Ja na memoria, as proximas respostas vem rapido.
Descarrega sozinho
Apos um tempo ocioso, o Ollama libera a RAM — ai a proxima vira "cold" de novo.
💡 Dica pratica
Se a primeira resposta parecer "travada", espere — provavelmente e so o 1o load. A velocidade depende do seu hardware: quanto mais rapida a memoria e o chip, mais rapido carrega e responde. Use ollama ps pra ver se o modelo esta carregado neste momento.
Conceitos-chave
Carregar o modelo do disco pra RAM.
Frio (carregando) e lento; quente (na RAM) e rapido.
Mostra qual modelo esta carregado agora.
A velocidade e a da sua maquina.
🗑️ Gerenciar modelos
Como modelos sao gratis, voce vai testar varios — e cada um ocupa gigabytes. Tres comandos cuidam disso: ollama list mostra o que voce baixou, ollama ps mostra o que esta rodando agora, e ollama rm apaga um modelo pra liberar disco.
🎯 Code-run: listar, ver e apagar
Objetivo: ver seus modelos e apagar um que nao usa mais. Cole conforme precisar:
ollama list # o que voce baixou (nome + tamanho)
ollama ps # o que esta carregado na memoria agora
ollama rm <modelo> # apaga; ex.: ollama rm qwen3:30b-a3b-q4_K_MComo verificar: depois do rm, rode ollama list de novo — o modelo apagado some da lista e o disco e liberado.
Atencao: troque <modelo> pelo nome exato do que aparece no ollama list. O rm apaga de verdade — pra usar de novo, voce precisa baixar (pull) outra vez.
✈️ Verificacao final: responde offline?
Prova de que e local mesmo: desligue o wi-fi, rode ollama run qwen3:30b-a3b-q4_K_M e faca uma pergunta. Se responder sem internet, voce confirmou que a inteligencia esta na SUA maquina — exatamente a promessa do curso.
Conceitos-chave
Lista os modelos baixados e seus tamanhos.
Mostra o que esta carregado na memoria.
Apaga um modelo e libera disco.
Sem internet, o modelo continua respondendo.
Auto-checagem (opcional): voce esta conversando no terminal e quer encerrar a conversa, voltando ao terminal normal. O que voce digita?
🎯 Resumo do modulo
ollama pull qwen3:30b-a3b-q4_K_M traz o modelo (~18 GB) pro disco, uma unica vez.ollama run ... abre o chat no terminal; /bye encerra. Ou use o app.list/ps/rm cuidam dos modelos; sem wi-fi, ele ainda responde.Proximo modulo:
2.4 — O modelo do agente: Qwen 3 Coder 64k