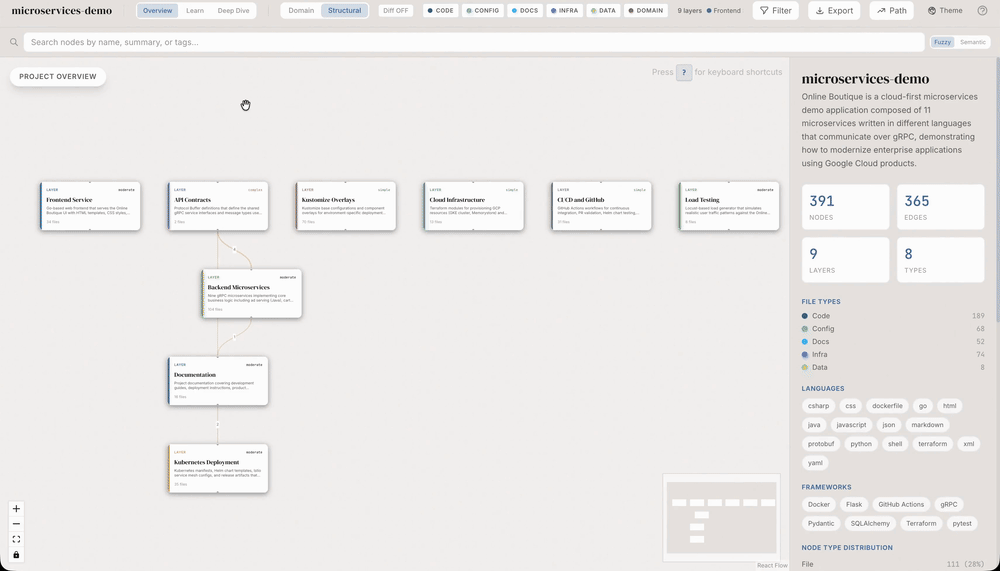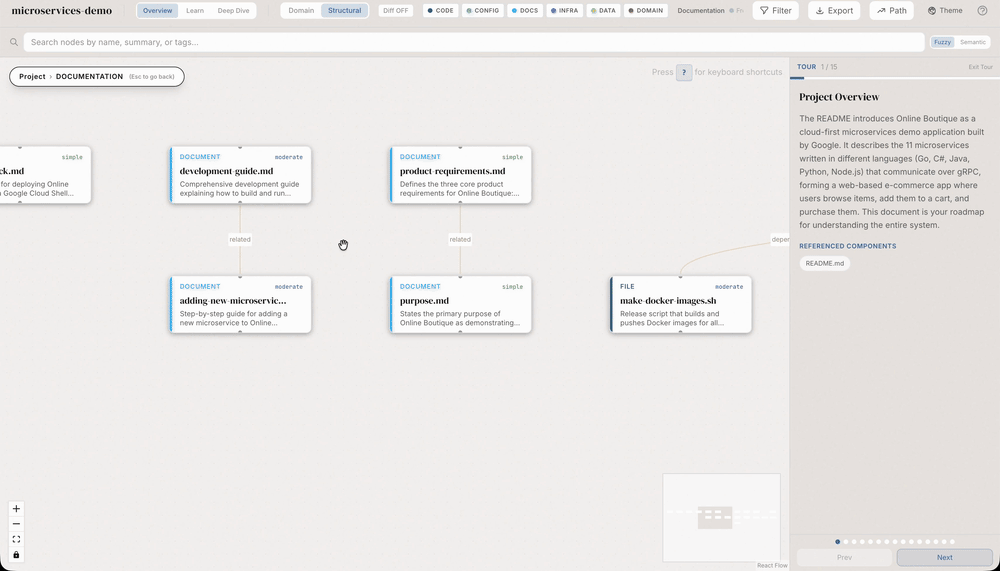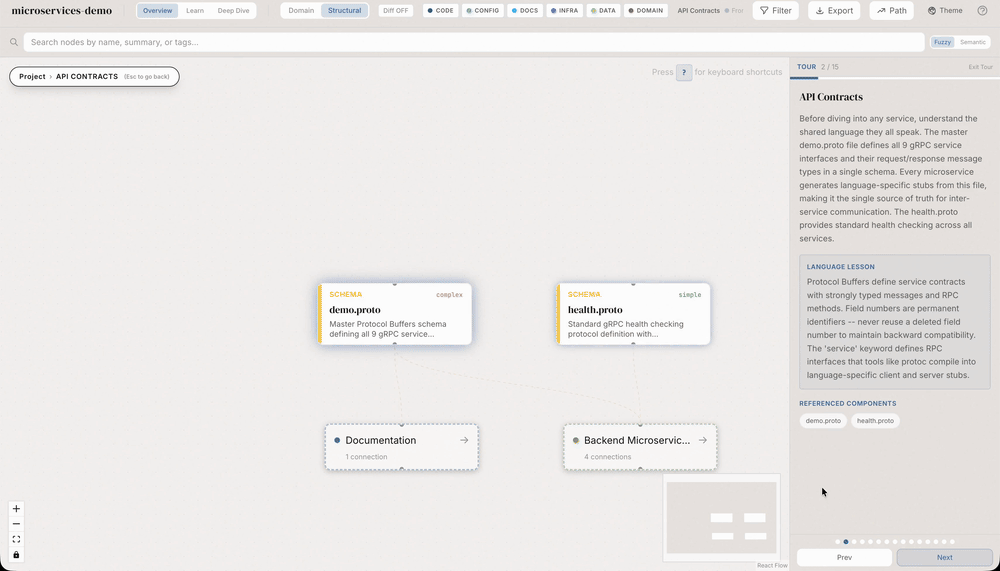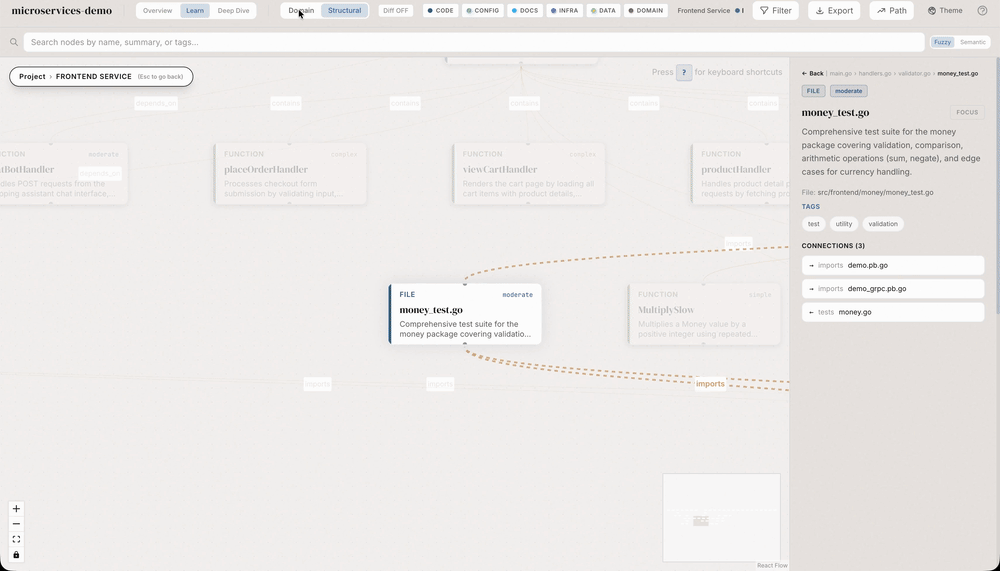
.understandignore, semantic batching e output chunking, a análise de 500 arquivos como este custaria ~529k tokens e dropparia edges no caminho.
🚫 .understandignore: sintaxe gitignore-like
Antes de pensar em otimizar prompt, elimine o que nem deveria estar sendo analisado. O .understandignore usa sintaxe idêntica ao .gitignore e some com vendor, dist, fixtures e geração de código.
🧠 Como funciona
O createIgnoreFilter(projectRoot) carrega patterns nesta ordem:
- 1.Hardcoded defaults — node_modules/, .git/, dist/, build/, *.lock, *.min.js, etc.
- 2..understand-anything/.understandignore — junto com o output
- 3..understandignore na raiz — alternativa visível no repo
Patterns somam. ! de negação no user file pode forçar inclusão (ex: !dist/ reanalisa dist/).
📄 Exemplo .understandignore
# Exclusões adicionais
docs/legacy/
**/__snapshots__/
**/*.generated.ts
storybook-static/
# Force-include algo que o default exclui
!dist/types.d.ts💡 Dica prática
Na primeira execução, o pipeline auto-gera um .understandignore comentado e pausa. Revise antes de continuar — 30 segundos de leitura podem economizar 10 minutos de análise inútil.
ignore💰 Onde os tokens somem (e como recuperar 85%)
Em projeto TS+React de 500 arquivos, o baseline é ~529.000 tokens de input. Metade é desperdício puro: o mesmo allProjectFiles repetido em cada batch.
📊 Dados de pesquisa — breakdown 500-file
- ~167.000 tokens (50%) — allProjectFiles × 67 batches (puro repeat)
- ~134.000 tokens (40%) — file-analyzer-prompt × 67 batches
- ~80.000 tokens (24%) — payload do tour builder
- ~68.000 tokens (20%) — addendums de linguagem × 67 batches
- ~58.000 tokens (17%) — graph reviewer recebendo grafo + inventário
- ~22.000 tokens (7%) — architecture analyzer
🔧 Cinco mudanças (C1–C5)
C1 Pre-resolve imports no scanner → mata 167k tokens repetidos
C2 Encolher file-analyzer prompt → -40% no prompt
C3 Lazy language addendum → só carrega se linguagem aparecer
C4 Summary cache p/ tour builder → reaproveita Phase 2
C5 Reviewer com inventory comprimido → -50% no Phase 6
Total: -85% a -90% em 500-file project🧠 Semantic batching com Louvain
Count-based batching (20-30 files/batch) quebra módulos no meio. Arquivos que se importam mutuamente acabam em batches diferentes — e o file-analyzer só vê edges dentro do batch. Calls / related / inherits / implements entre módulos somem.
✗ Count-based (antigo)
- ✗Files por contagem fixa (25 cada)
- ✗auth/login.ts no batch 3, auth/session.ts no 7 → edge perdida
- ✗Cross-module: só sobrevive
imports(recuperado pelo safety net) - ✗calls/related/inherits dropados silenciosamente
✓ Louvain (novo)
- ✓Community detection no grafo de imports
- ✓Módulo auth/* fica num único batch
- ✓Edges semânticas preservadas dentro da comunidade
- ✓neighborMap dá contexto cross-batch sem inflar token
📄 compute-batches.mjs (fase 1.5)
node $SKILL_DIR/compute-batches.mjs $PROJECT_ROOT [--changed-files=...]
Input: .understand-anything/intermediate/scan-result.json
Output: .understand-anything/intermediate/batches.json
Algoritmo:
1. Constrói grafo (nós=arquivos, edges=imports) com graphology
2. Roda Louvain modularity para detectar comunidades
3. Cada comunidade vira um batch (split se exceder threshold)
4. Anexa neighborMap (vizinhos próximos fora do batch)💡 Dica prática
Pura algorítmica — sem LLM. Roda em milissegundos mesmo com 500 arquivos. Se quiser incremental, passe --changed-files=... para batchar só o que mudou.
.understandignore remove ruído antes da análise, Louvain mantém cada módulo num único batch (preservando edges calls/related) e o chunking divide saídas grandes em batch-i-part-k.json para caber no budget de Write — evitando o "minimal output mode" do issue #159.
✂️ Output chunking: batch-i-part-k.json
Em LLM backends com output cap baixo (notório: Bedrock OPUS, max_tokens 4096-8192), o file-analyzer enche o budget de Write antes de terminar e entra em "minimal output mode" — dropando nodes/edges em silêncio.
⚠️ Sintoma do issue #159
"Batch X failed (output limit)" aparece no log. O grafo final tem buracos. Pior: o agente não falha visivelmente — só produz output pobre. Bedrock OPUS em projetos de 100+ arquivos pega muito.
🛠️ Solução: self-check + split
O file-analyzer agora:
- 1.Estima tamanho do JSON antes de chamar
Write - 2.Se exceder threshold, escreve
batch-i-part-1.json,part-2.json... - 3.Cada part é JSON válido completo (nodes + edges parciais)
- 4.O
merge-batch-graphs.pyjá aceita glob multi-part — zero código novo
📄 Naming convention
intermediate/
├── batch-1.json # cabe inteiro — single file
├── batch-2-part-1.json # batch grande dividido
├── batch-2-part-2.json
├── batch-2-part-3.json
└── batch-3.json
Merge regex aceita ambos: batch-(-part-)?.json 📦 Import map pré-resolvido (deep dive em C1)
A maior economia vem do C1: parsear imports na Fase 1 e escrever um importMap no scan-result.json. Cada batch recebe só os imports relevantes, não a lista de 500 arquivos.
📄 scan-result.json — campo novo
{
"importMap": {
"src/index.ts": ["src/utils.ts", "src/config.ts"],
"src/utils.ts": [],
"src/components/App.tsx": ["src/hooks/useAuth.ts", "src/store/index.ts"]
}
}
Regras:
- Keys e values são project-relative paths
- Externals (node_modules, builtins) são omitidos
- Por-linguagem: TS import/require, Python import/from, Go import blocksStep 8 no scanner
Determinístico, não-LLM
Para cada arquivo source: lê conteúdo, extrai imports per-language, resolve paths relativos contra a lista descoberta.
Phase 2 mudou
Per-batch context
file-analyzer recebe só o subset do importMap relativo aos arquivos do batch. -2.500 tokens × 67 batches.
Safety net
recover_imports_from_scan
Em merge-batch-graphs.py, recupera deterministicamente edges imports a partir do importMap mesmo se o LLM não emitiu.
💡 Dica prática
O safety net não recupera calls/related/inherits/implements — esses dependem do LLM. Por isso semantic batching (tópico 3) é complementar ao C1: um trata imports, o outro semântica.
📈 Medir antes de otimizar
Otimizar sem medir é chute. Conte tokens por fase antes e depois de cada mudança. Sem profile, você acha que o problema é o LLM quando é o file list repetido 67 vezes.
📏 Métricas mínimas
- •Tokens input por fase — somar prompts + payloads
- •Tokens output por fase — detectar quando bateu cap
- •Wall time por fase — paralelização ajudando?
- •Cobertura de edges — % de edges semânticas vs apenas imports
✓ FAZER
- ✓Benchmark fixo (500-file TS project) reproduzível
- ✓Comparar antes/depois com a MESMA seed
- ✓Logar contagens em
intermediate/metrics.json - ✓Regression test no CI: tokens não podem aumentar 10%+
✗ EVITAR
- ✗Comparar runs com projetos diferentes
- ✗Confundir output cap com qualidade do LLM
- ✗Otimizar fase 7% (architecture) antes da fase 50% (file list)
- ✗Aceitar regressão sem isolar a causa
💡 Dica prática
Use o próprio u-any como benchmark recorrente — ele tem TS + agentes + dashboard. Roda em ~5 min e cabe nos limites de qualquer backend. Bom para CI smoke test.
📌 Resumo do módulo
Próximo módulo:
3.3 — Camada de domínio e escala visual: business domain knowledge + graph layout scaling