Mapa da trilha
Conteúdo detalhado
🧩 Estendendo o Understand Anything: language extractors e custom agents
Aprenda a registrar uma nova linguagem no PluginRegistry, escrever um extractor tree-sitter próprio e criar agentes customizados que entram no pipeline gravando em .understand-anything/intermediate/.
A arquitetura do Understand Anything é language-neutral: LanguageConfig + PluginRegistry em packages/core/src/languages/ aceitam configs por linguagem com gramática WASM, node types e conceitos.
Sem entender a arquitetura, você duplica código nos prompts em vez de registrar uma vez no registry. Saber onde plugar evita forks desnecessários.
Config-first com escape hatch • detecção por extensão • snippets de prompt por linguagem • escape para AST exótica via customAnalyzer.
Cada linguagem nova precisa de uma gramática tree-sitter compilada em WASM e dos node types corretos para functions, classes, imports e exports.
Sem gramática válida, o file-analyzer regride para análise puramente textual e perde edges estruturais. WASM é obrigatório porque native bindings quebram em darwin/arm64 + Node 24.
Pacote npm da gramática • mapeamento de node types • binding via Parser.Language.load() • teste com fixtures pequenas antes de mandar prod.
O file-analyzer combina um prompt base genérico com um snippet markdown da linguagem (skills/understand/languages/python.md, etc.) com conceitos idiomáticos.
Sem snippet por linguagem, o LLM aplica conceitos de TS (barrel files, generics) em código Python e gera resumos ruins. Snippet curto = ganho enorme.
Conceitos idiomáticos da linguagem • exemplos de função/classe típicos • file patterns especiais (pyproject.toml, go.mod) • tom didático.
Agentes vivem em understand-anything-plugin/agents/*.md com frontmatter YAML (nome, description, tools) e um corpo de prompt que descreve a tarefa.
Customizar agentes sem entender o contrato leva a falhas silenciosas. O campo model é omitido de propósito — model: inherit quebrava opencode (issue #167).
Frontmatter mínimo • tools declaradas • prompt como contrato • output sempre via Write em .understand-anything/intermediate/.
O fluxo do /understand é orquestrado em fases (scan → batches → file-analyzer → architecture → tour → review). Cada fase lê/escreve em intermediate/.
Saber em que fase enfiar seu agente determina se ele recebe scan-result, batches, ou o grafo assembled. Plugar no lugar errado custa retrabalho.
Contrato JSON entre fases • idempotência • cleanup automático após assembly • falha de uma fase não pode bloquear graph reviewer.
Toda extensão precisa de fixture em tests/ + schema validation no carregamento do grafo + vitest snapshots dos outputs intermediários.
Sem teste, uma gramática nova pode quebrar projects existentes em silêncio. O schema validator banner do dashboard só pega depois — caro.
Fixture mínima por linguagem • snapshot de scan-result.json • vitest --filter @understand-anything/core • dogfood no próprio repo.
⚡ Performance e escala: .understandignore, token reduction, semantic batching, output chunking
Técnicas para rodar o pipeline em monorepos de 500+ arquivos sem estourar contexto: exclusões cirúrgicas, pré-resolução de imports, batching por comunidade Louvain e chunking de saída.
Arquivo opcional em .understand-anything/.understandignore ou na raiz que adiciona patterns gitignore-style aos defaults hardcoded.
Sem ele, você analisa vendor/, fixtures e generated code à toa — desperdiçando tokens e poluindo o grafo. Negação com ! força inclusão.
Sintaxe igual .gitignore • patterns aditivos sobre defaults • starter file auto-gerado comentado • pausa antes da análise para revisar.
Cinco mudanças (C1–C5) que reduzem tokens em ~85% em projetos de 500 arquivos: pré-resolver imports, encolher prompts, summary cache, compressão e reuso.
Em 500 arquivos, baseline = 529k tokens — 50% só repetindo o allProjectFiles em cada batch. C1 sozinho elimina esse desperdício.
Import map no scan-result.json • prompts compactos • cache deterministico • backward-compatible com knowledge-graph.json.
Fase 1.5 (compute-batches.mjs) roda Louvain no grafo de imports e agrupa arquivos por comunidade, não por count.
Count-based quebra módulos no meio: edges entre auth/api/store ficam fora de qualquer batch e somem do grafo. Louvain mantém o módulo inteiro junto.
Louvain modularity • neighborMap por batch • graphology npm package • cobertura semântica de edges calls/related/inherits.
Quando o batch JSON excede o budget de Write (notório em Bedrock OPUS max_tokens=4096), o file-analyzer auto-divide em batch-i-part-k.json.
Sem chunking, o agente entra em "minimal output mode" e dropa nodes/edges silenciosamente — exatamente o sintoma do issue #159.
Self-check de tamanho antes do Write • naming multi-part compatível com merge • merge-batch-graphs.py já aceita glob multi-part.
O scanner script parseia imports na Fase 1 e escreve um importMap em scan-result.json com paths já resolvidos.
Cada batch recebia 2.5k tokens de file list × 67 batches = 167k tokens desperdiçados. O importMap entrega só os imports daquele batch.
Resolução determinística • externals omitidos • keys = project-relative paths • por-linguagem (TS, Python, Go).
Métrica básica: contar tokens de input por fase, comparar antes/depois de cada otimização. Logs intermediários ajudam a localizar regressões.
Otimizar sem medir é chute. Sem profile, você acha que o problema é o LLM quando na verdade é o file list repetido 67 vezes.
Token breakdown por fase • benchmark 500-file project • dogfood antes de release • regression test no CI.
🌐 Camada de domínio e escala visual: business domain knowledge + graph layout scaling
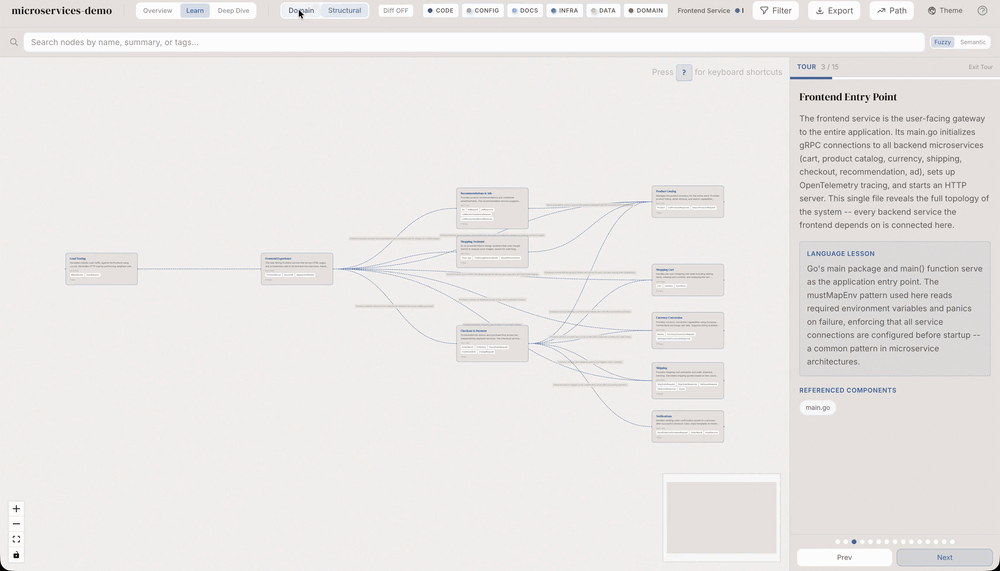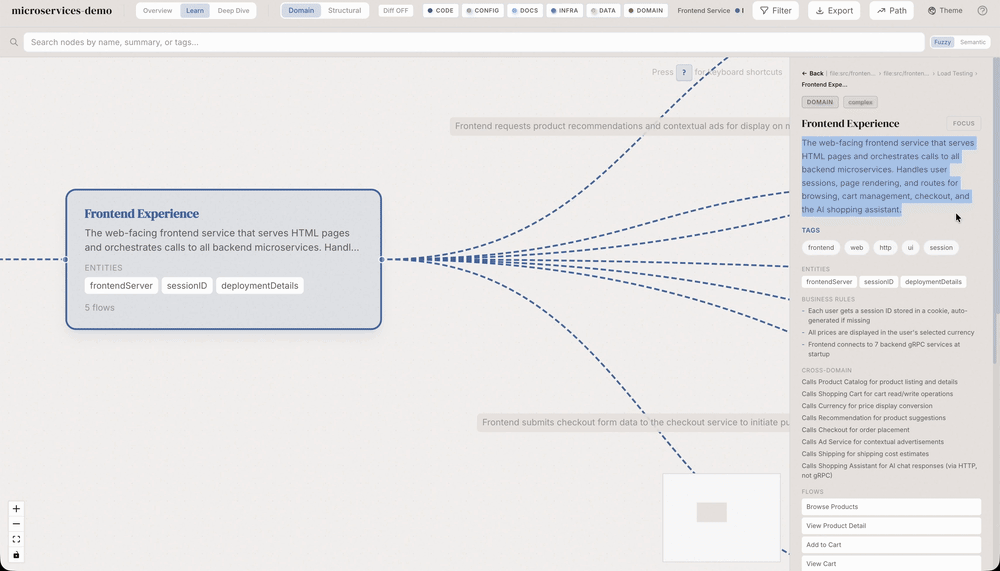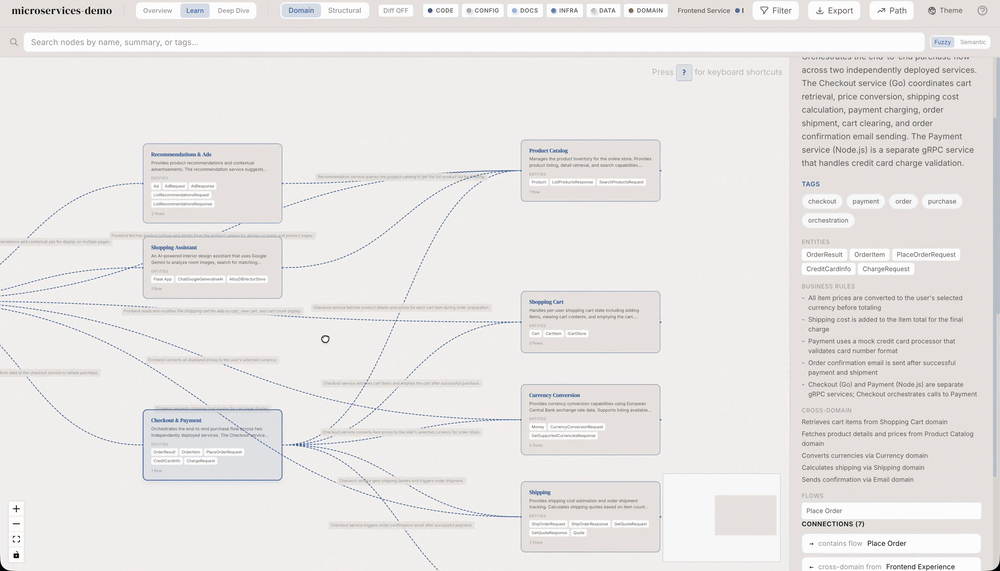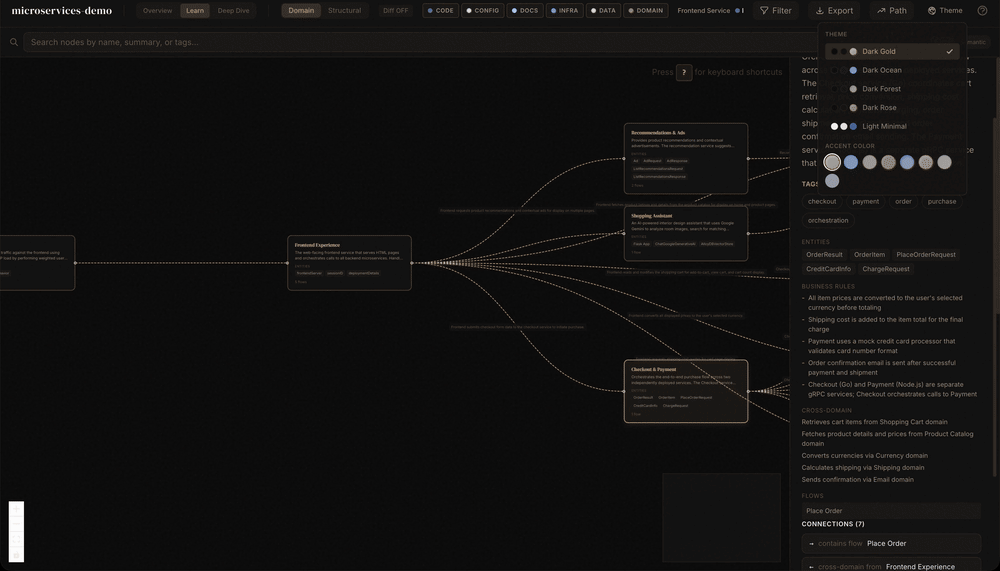
Anote o grafo com conhecimento de negócio (domain/flow/step), alterne entre visão estrutural e de domínio, e use ELK + containers para escalar layout até milhares de nós.
Três tipos novos de nó (domain, flow, step) e quatro edges (contains_flow, flow_step, cross_domain, implements) ligando ao grafo estrutural.
Edges de import só repetem o que a IDE mostra. Domain knowledge responde "o que esse código faz" em vez de "como ele se conecta".
Domain = cluster (Order Management) • Flow = processo (Create Order) • Step = passo (Validate input) • implements aponta para nó estrutural.
Domain data vive em domain-graph.json separado, usando o mesmo tipo KnowledgeGraph estendido. Dashboard detecta ambos e oferece toggle.
Manter separado evita poluir o grafo estrutural e permite que /understand-domain rode standalone, sem rodar o pipeline pesado.
Schema compartilhado • search e validation funcionam para ambos • toggle Domain ↔ Structural • drill-down via edge implements.
Substituição do applyDagreLayout pelo ELK em todas as views structural-style: overview, DomainGraphView e layer-detail.
Dagre TB enfileira 50+ nós no mesmo rank numa linha de milhares de px — ilegível. ELK distribui em 2D com algoritmos modernos (layered, force, mrtree).
ELK.js no browser • configuração por view • mesmo schema do grafo • KnowledgeGraphView fica em force layout (não toca).
Layer-detail ganha containers derivados de pasta (estratégia default) com fallback para community detection. Cross-container edges são agregadas.
Sem containers, 100+ nós soltos não têm âncora visual. Folder containers dão ao leitor o "onde estamos" instantaneamente.
Folder strategy default • community fallback • edges agregadas por padrão • parentId no React Flow para parent-child.
Stage 1 layouta só os containers (rápido). Stage 2 layouta filhos sob demanda quando o usuário clica, dá zoom, busca ou abre tour.
Layoutar 1000+ nós de uma vez trava o browser. Two-stage entrega first paint rápido e adia trabalho.
Pure & memoized • só recomputa em mudança topológica • cache por container • visual state é overlay separado O(n).
Falhas de layout são modeladas como GraphIssue (o mesmo modelo do schema validator) e renderizadas no banner do dashboard.
Sem GraphIssue, o usuário só vê tela branca quando o ELK falha — não dá pra debugar nem reportar. Mensagem clara > silêncio.
Banner de erro padronizado • sem telemetria remota (open-source) • fallback para grafo flat se container falhar • mensagem actionable.