🎚️ Escolher o modelo certo pro seu hardware
Antes de gastar tempo (e disco) baixando 18 GB, vale parar 5 minutos para descobrir o que a sua maquina aguenta. Neste modulo voce vai ler o proprio hardware, pedir uma recomendacao ao Hermes, entender os niveis de esforco e aplicar a regra de ouro do headroom: nunca encher a RAM ate o talo.
🖥️ Conheca seu hardware
Tudo comeca com um numero: quanta memoria (RAM) voce tem. E a RAM, mais do que o chip, que decide qual modelo cabe na sua maquina. No Mac, basta abrir o menu Apple → "Sobre este Mac" e ler a linha de memoria e o chip. No Windows, a tecla rapida e Ctrl+Shift+Esc → aba "Desempenho" → "Memoria".
Novo aqui? "RAM" e a memoria de trabalho do computador — onde o modelo precisa caber inteiro para rodar rapido. Nos Macs com chip Apple, a memoria e "unificada", ou seja, compartilhada entre CPU e GPU; por isso aquele numero unico (ex.: 36 GB) e o que conta.
Conceitos-chave
Memoria de trabalho; e ela que define qual modelo cabe.
Influencia a velocidade; nos Macs M, a memoria e unificada.
Onde ler chip e memoria em segundos.
O modelo + o contexto precisam caber nesse numero.
🤝 Peca uma recomendacao
Voce nao precisa decorar tabela nenhuma. O atalho e mostrar seu hardware ao proprio Hermes (um print do "Sobre este Mac" basta) e pedir: "quais modelos rodam bem aqui?". Ele cruza a sua RAM com o tamanho dos modelos e devolve uma lista pronta.
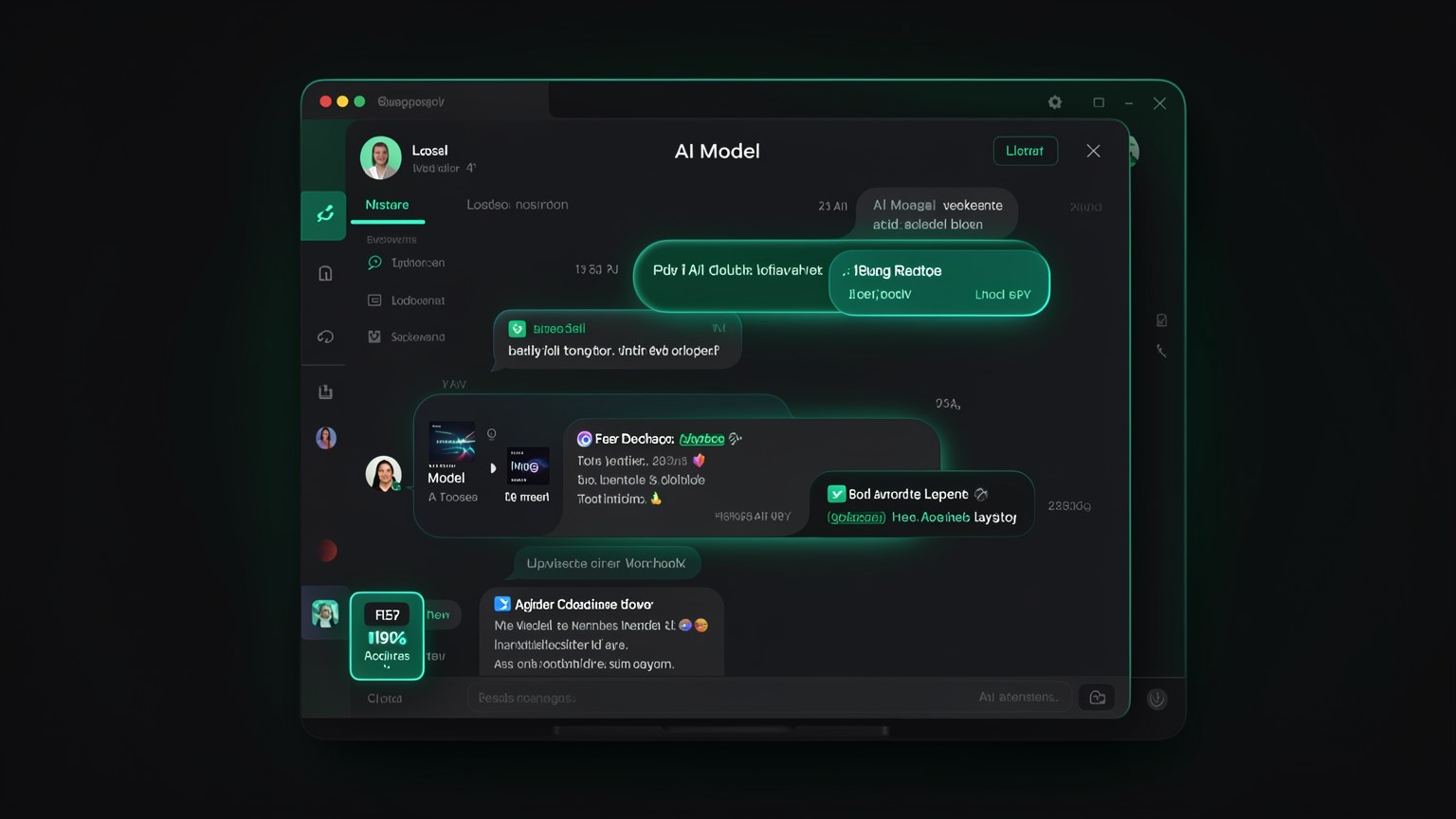
📊 Exemplo real: M4 Max 36 GB
Para uma maquina com 36 GB, o Hermes costuma sugerir opcoes como estas — todas modelos abertos:
Mais capaz, pesa mais.
Rapido e equilibrado (o do video).
Leve, sobra RAM.
Meio-termo da lista.
💡 Dica pratica
Sem o Hermes a mao? A regra grosseira: um modelo quantizado em q4 ocupa, em GB, mais ou menos o numero de bilhoes de parametros vezes ~0,6. Um "30B" fica em torno de 18 GB — por isso ele cabe (com folga) numa maquina de 36 GB.
Conceitos-chave
Mostrar o "Sobre" e deixar o agente sugerir.
Varios tamanhos, voce escolhe pelo headroom.
Qwen, Mistral, Gemma — todas open weights.
~0,6 GB por bilhao em q4 — conta de padaria.
🎚️ Niveis de esforco
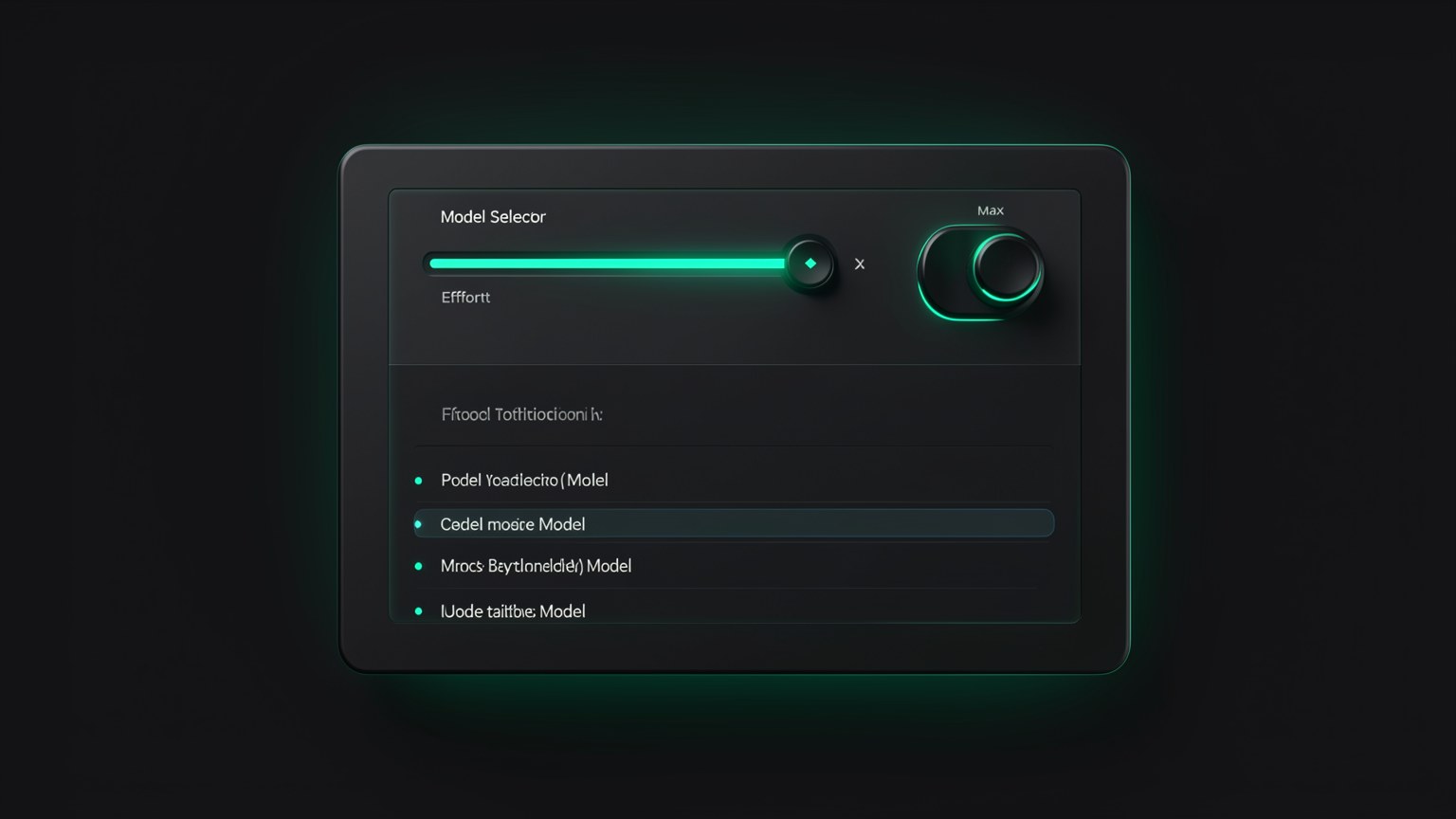
Escolher o modelo e so metade da historia. O seletor do Hermes ainda te deixa ajustar quanto esforco ele coloca em cada resposta — de Minimal a Max — alem de dois toggles: Thinking (pensar mais antes de responder) e Fast (priorizar velocidade).
Minimal / Low / Fast
Respostas rapidas, gasta menos. Bom para tarefas simples e para nao esquentar a maquina.
Medium
O equilibrio do dia a dia — qualidade boa sem demorar demais.
High / Max / Thinking
Maximo de raciocinio para problemas dificeis. Demora mais e pesa mais na maquina.
Novo aqui? "Effort" (esforco) nao troca o modelo — troca quanto ele "se esforca" antes de responder. "Thinking" e o modo em que o modelo raciocina passo a passo (aquele "Thought for X seconds" que voce ve depois). "Fast" e o oposto: corta o raciocinio para responder ja.
Conceitos-chave
Minimal → Max, a profundidade da resposta.
Pensa mais antes de responder.
Prioriza velocidade sobre profundidade.
Afina sem precisar baixar outro.
⚖️ A regra do headroom
Aqui esta a regra de ouro deste modulo: deixe folga de RAM. O modelo precisa caber na memoria com sobra para o sistema operacional, o navegador e o resto. Encher a RAM ate o talo faz a maquina "swapar" para o disco e tudo fica lento — inclusive o modelo.
A esquerda, um modelo de ~18 GB numa maquina de 36 GB deixa folga para o sistema — tudo voa. A direita, um modelo grande demais enche a RAM, forca o uso do disco (swap) e tudo fica lento. Por isso: prefira sobrar memoria.
✓ Cabe com folga
- ✓Modelo + contexto ocupam bem menos que a RAM total.
- ✓Sobra memoria para o sistema e os apps abertos.
- ✓Respostas rapidas, maquina responsiva.
- ✓Da para subir o contexto (ex.: 64k) sem travar.
✗ Estoura a memoria
- ✗O modelo quase enche toda a RAM disponivel.
- ✗O sistema comeca a usar disco (swap) como memoria.
- ✗Respostas lentas e a maquina inteira engasga.
- ✗Subir o contexto pode simplesmente nao caber.
O metodo certo e barato: baixar → testar → apagar. Como o uso e gratuito, experimente um modelo, veja se a maquina aguenta com folga, e se nao gostar, apague. Explorar nao custa nada — so o tempo de download.
⌨️ Copy-run: ver e apagar modelos
Objetivo: listar o que voce ja baixou e remover um modelo que nao deu certo, liberando disco e RAM.
# 1) ver tudo que esta no disco
ollama list
# 2) apagar um modelo que voce nao vai usar
ollama rm <modelo>
# ex.: ollama rm gemma3:27bComo verificar: rode ollama list de novo — o modelo apagado some da lista. Troque <modelo> pelo nome exato que aparece em ollama list.
Conceitos-chave
Folga de RAM para o sistema respirar.
Usar disco como memoria — o que deixa tudo lento.
O ciclo barato de explorar modelos.
Apaga um modelo e devolve o disco.
🏃 Rapido vs capaz: o que e q4_K_M
Voce vai ver nomes como qwen3:30b-a3b-q4_K_M e se perguntar o que e aquele sufixo. O q4_K_M indica que o modelo foi quantizado: comprimido para ocupar menos memoria, trocando um tiquinho de precisao por muito menos peso.
Novo aqui? "Quantizar" e guardar os numeros internos do modelo com menos casas — em vez de 16 bits por valor, usa 4 bits (o "q4"). O modelo encolhe bastante e, na pratica, a qualidade quase nao cai. O "K_M" e so a variante do metodo de compressao (um bom equilibrio padrao).
📏 Lendo um nome de modelo
- •
qwen3— a familia (Qwen, versao 3). - •
30b— 30 bilhoes de parametros (o tamanho do "cerebro"). - •
a3b— variante "ativa 3B" (mistura de especialistas: roda rapido). - •
q4_K_M— quantizado em 4 bits: menor e mais leve.
💡 Dica pratica
Entre duas versoes do mesmo modelo, a quantizada (q4) quase sempre e a escolha certa no local: voce cabe um modelo maior na mesma RAM e a diferenca de qualidade e pequena. Versoes "fp16" (sem quantizar) so valem se voce tem memoria sobrando de verdade.
Conceitos-chave
Comprimir o modelo para ocupar menos RAM.
4 bits, variante equilibrada — o padrao do local.
O "30B" = 30 bilhoes; tamanho do cerebro.
Troca pequena de qualidade por muito menos peso.
🎯 Qual baixar primeiro
Para nao travar na escolha, vai uma recomendacao concreta: comece com o qwen3:30b-a3b-q4_K_M. E o "modelo rapido" do video — equilibrado, quantizado, com a variante a3b que o deixa veloz, e que cabe com folga em maquinas de ~32 GB ou mais. Da pra trocar depois; o importante e ter um primeiro modelo rodando.
🧩 O plano em uma frase
Leia sua RAM → peca a recomendacao → escolha um modelo que cabe com folga → baixe o qwen3:30b-a3b-q4_K_M como primeiro. No modulo 2.3 voce baixa e conversa com ele de verdade.
E o modelo do agente (com 64k de contexto) vem no modulo 2.4 — esse exige um preparo extra.
Atalho honesto: nao existe "o melhor modelo" universal. O melhor e o que cabe com folga na SUA maquina e responde rapido o suficiente para voce nao desistir. Comece pelo recomendado e ajuste com o tempo.
Conceitos-chave
qwen3:30b-a3b-q4_K_M — equilibrado e rapido.
~18 GB numa maquina de ~32 GB+.
Comece simples, ajuste depois.
Os 64k sao do modulo 2.4.
Auto-checagem (opcional): qual e a melhor escolha de modelo para a sua maquina?
🎯 Resumo do modulo
Proximo modulo:
2.3 — Baixar e conversar com seu 1o modelo